*Note: All links imbedded in the text are also available with full URLs at the end of this document
What is Data Citation and Why Is It Important?
The current trend towards improved transparency and reproducibility in science is pushing researchers and institutions to develop new strategies for managing the data they produce. Increasingly, publishers insist on access to the datasets underpinning submissions, and national funding agencies are establishing policies requiring the open sharing of data as a condition of receiving grants. These changes are driving the creation of new tools to ensure data is findable, accessible, and reusable and remains so into the future.
Much like citations for published works, data citations based on persistent identifiers (PIDs) provide a way to find the exact source material used in a given piece of research. For digital objects, PIDs are needed to provide a single, consistent “location” where that object can be found on the web. One of the most commonly used PIDs is the Digital Object Identifier, or DOI, a permanent link which will always resolve to a particular resource (or a comprehensive record for that resource).
Dynamic Data Citation
Persistent identifiers are straightforward to create for finished objects, such as a published paper or complete dataset. Dynamic data that changes over time, like ONC’s continuously accumulating data streams, are more difficult to affix identifiers to, as the dataset is constantly evolving. To reliably and reproducibly cite dynamic data requires more detailed information about specific subsets of the data, such as the exact date and time the data was retrieved, and any search parameters used in selecting a particular subset. However, it’s not feasible to mint a new DOI for every single change to an evolving dataset, and preserving complete previous versions of all data is beyond any institution’s storage capacity.
In February 2015, the Research Data Alliance (RDA) Working Group on Dynamic Data Citation (WGDC) released a set of 14 recommendations to guide best practices for persistently and reproducibly identifying these kinds of datasets. The recommendations rest on 3 pillars:
- Versioning - Major changes to a dataset are marked with a new version number.
- Timestamping - Queries made to the database are saved along with metadata about exactly when and how they were made.
- Query Preservation - PIDs are assigned not only to the whole dataset, but also to each time-stamped query used to extract a particular data subset from the repository’s database.
Combining these strategies, we can narrow down the parameters of a dataset until it exactly matches the state it was in when it was previously retrieved. New version releases mark significant changes to the dataset, whether to the data itself or the ways in which it was processed. Timestamps for the date and time the dataset was accessed further refine recall within the context of the frequent, smaller changes that don’t necessitate a new version. Finally, assigning a persistent identifier to each individual query - an actual data request sent to the database - allows previously accessed subsets to be re-created with ease, eliminating the need to painstakingly replicate complex search parameters by hand.
Data Availability Statements
What is a Data Availability Statement (DAS)?
- A Data Availability Statement, also commonly referred to as a Data Access Statement tells the reader whether the data created, procured or used for a research project can be accessed. If yes, how and where? These statements are important because they support reuse, validation and citation of the reported work. They allow the readers an opportunity to verify the legitimacy of your paper’s underlying data. Other researchers who wish to reuse the information can validate your findings and conduct further research. Additionally, it helps in improving the chances of the work being properly cited. Moreover, a complete Data Availability Statement increases transparency, allows compliance with journal policies, promotes trust, and encourages good scientific practice.
What are the benefits to authors of data availability statements?
- Data availability statements help authors demonstrate compliance with funder policies on data archiving, where applicable, and also shows
compliance with Nature Research editorial policies. - Data availability statements provide more consistent links between public datasets and journal articles to increase the visibility of research.
What are the benefits to readers of data availability statements?
- Data availability statements provide more transparent and consistent information about where and how data supports published articles.
Are Data Availability Statements required by Journals?
- Most journals today mandate a Data Availability Statement, where authors provide all the necessary information to reproduce the study.
How do I submit/include?
- Include your data availability statement within the text of your manuscript, before your ‘References’ section. So that readers can easily find it, please give it the heading ‘Data availability statement’.
Data Availability Statements are not the same thing as, or meant to replace data citation, they are to be used together.
| Data Availability Case | Template Data Availability Statement |
|---|---|
| Data openly available in a public repository that issues datasets with DOIs | The data that support the findings of this study are openly available in [repository name e.g “figshare”] at http://doi.org/[doi], reference number [reference number]. |
| Data available on request due to privacy/ethical restrictions | Due to its proprietary nature <or ethical concerns>, supporting data cannot be made openly available. Further information about the data and conditions for access are available at the \\\repository name\\\{} at \\\insert DOI here\\\{}. OR combination with: Data generated or analyzed during this study are not publicly available due to [REASON(S) WHY DATA ARE NOT PUBLIC e.g., confidentiality agreement with research collaborators] but are available from the corresponding author on reasonable request [LIST ANY CONDITIONS]. |
| Data is not available | Data generated or analyzed during this study are not available due to the nature of this research [SPECIFY ETHICAL/LEGAL/COMMERCIAL RESTRICTIONS]. |
| No data used | Data sharing not applicable to this article as no datasets were generated or analyzed during the current study. |
Landing Pages
Dataset Landing Page video walkthrough
Dataset Landing Page
The landing page describes the high level information (‘metadata’) associated with a dataset. ONC defines a dataset as one deployment of one device, e.g. 'Aanderaa Optode 3830 (S/N 911) deployed at Folger Passage on 11-Sep-2015, recovered 02-May-2017'. The Landing Page is discoverable through the Oceans 3.0 User Interface:
- Navigate to the Data Search page, select appropriate location and instrument, click on the 'Detail' link,
- Details link resolves to the Device Listing Page. Navigates to the Sites tab,
- Select the appropriate siteDeviceID link. This will resolve to the Site Device page, which includes a linked DOI,
- Select the DOI, and this will resolve to the Landing Page for that dataset
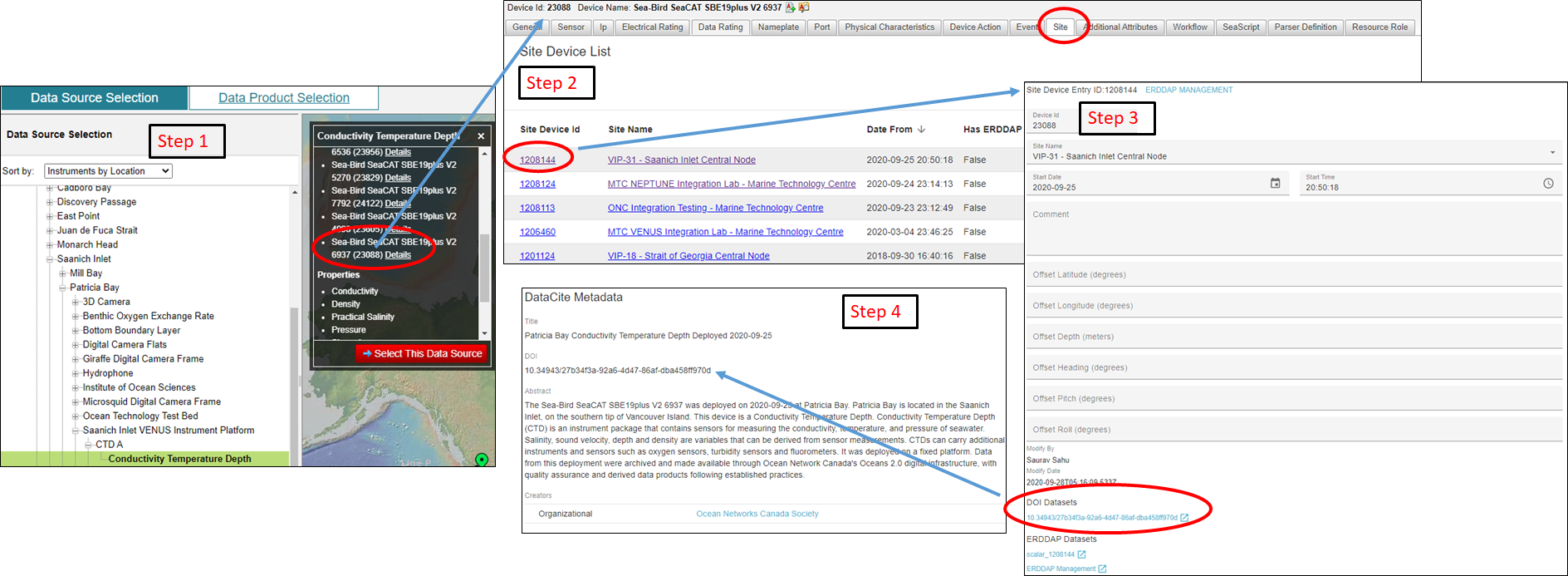
Alternatively, if the DOI is provided (i.e., in a citation), users can search for the DOI of any dataset at https://data.oceannetworks.ca/DatasetLandingPage.
Example landing page for a DOI
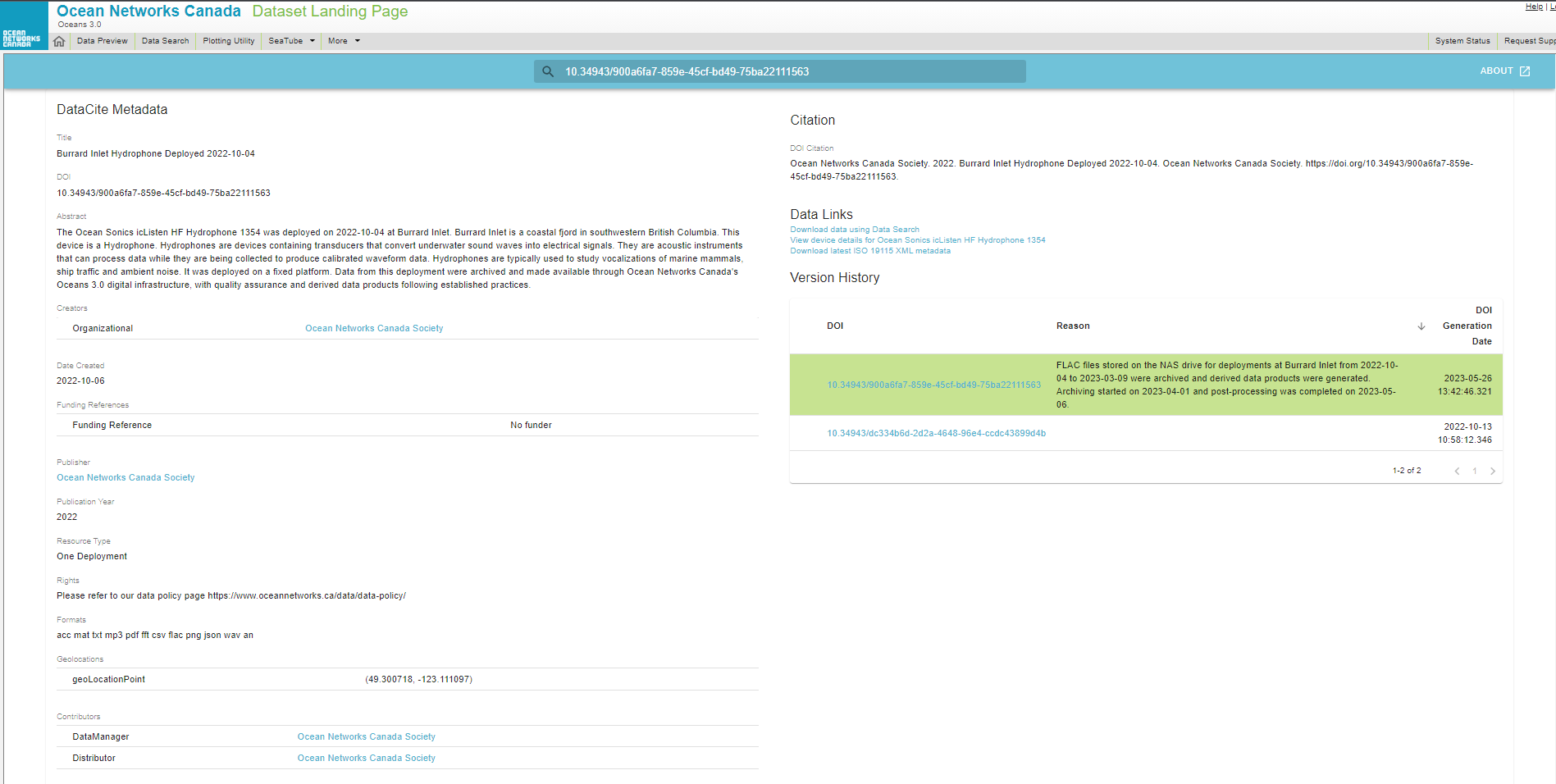
Landing Page Metadata Sections
- The Title is composed of several pieces of information describing the dataset: Deployment Location, Device Category, and Date of Deployment.
- The DOI is the persistent identifier for the entire dataset. ONC DOIs all begin with the prefix 10.34943. The DOI is included in the provided data citation.
- The Abstract provides the user with a high level description of the device deployment from which the data was collected, to help them identify if this dataset is appropriate for their purposes. The abstract consists of the device name, the date and site it was deployed at, a description of the site, the device category, a description of the device category, what type of platform it was deployed on (fixed, mobile, profiler), and a note about where the data was archived.
- The Creators are listed in this section. ONC has data partners who should be attributed appropriately within the landing page and citation. The Creator(s) is/are linked with their ROR, which resolves to their entry on the ROR portal.
- The Date Created section displays the date the version of the data became publicly available.
- The Funding References section includes any/all funding organizations that contributed to the data collection and archival.
- The Publisher section specifies the organization that made the data available to the public. The Publisher(s) is/are linked with their ROR, which resolves to the ROR entry on their portal.
- The Publication Year is the year that the version of the dataset became publicly available.
- The Resource Type will always be ‘One Deployment’, specifying that the dataset only covers the length of a single deployment of the instrument.
- The Rights section points towards ONC’s Data Usage Policy, helping users understand the constraints and licensing of the associated dataset.
- The Formats section provides a list of the types of file formats the data is available in.
- The Geolocations provide the user with the longitude and latitude of the area the data was collected. Note: for mobile platforms, multiple points are provided to create a polygon or a bounding box.
- The Contributors section lists the organization(s) and roles involved with data collection and archival. The Contributors are linked with their ROR, which resolves to the ROR entry on their portal.
- The Citation section provides the actual citation that ONC and our data partners would like users to use in outputs utilizing the data associated with the particular DOI. More and more publishers are requiring datasets to be referenced with DOIs as support for the COPDESS statement grows. Users can simply copy and paste the citation directly into their resources, bibliography, citation list, etc. The citation text is created according to the ESIP Data Citation Guidelines for Earth Sciences recommended best practices.
- The Data Links section provides the user with direct links to:
- Download data using Data Search: resolves to the instrument and deployment location in the Data Search page on Oceans 3.0
- View device details for ____: additional metadata and details about the instrument associated with the DOI, on its Device Listing page on Oceans 3.0
- Download latest ISO 19115 XML metadata: download the machine-readable ISO 19115 metadata record for the dataset. This metadata record is produced on-the-fly, meaning that it's content is based on the most current database entries.
- The Version History section provides details about any updates to the dataset after it was initially assigned its DOI, i.e., reprocessing of the data. The reason for the new version and the date it took place are also provided.
Query PID Landing Page
The landing page for a Query PID has all the same dataset metadata as a DOI landing page, plus some additional information. Query Details describe the specific filters and parameters used in a particular query/search. To see this page, enter any Query PID into https://data.oceannetworks.ca/DatasetLandingPage.
Example landing page for a Query PID

Query-PID Specific Metadata Sections (yellow box):
- The Data Product section lists the specific type of output(s)/product(s) selected for download in the query parameters.
- The Query Date Created section provides the date the query was first run.
- The Query Date From/To sections defines the timeframe of the data subset extracted from the complete dataset.
- The Variables section includes the variables the user selected from the list of available recorded measurements.
- The Format section lists the file format the user selected to download. If multiple file formats are selected, each output will receive it's own Query PID.
- The Data Product Options section shows the options selected by the user for the data to be downloaded:
- Data Gaps: whether missing/bad data is filled by a placeholder representing an undefined value, or left as it is in the raw data.
- Quality Control: whether clean or raw data was chosen
- Processing: what type of data processing was chosen, if any, from available options for that dataset, e.g. averaged hourly
- The Citation section provides the user with the preferred Query Citation to use, including the Query PID and the Access date.
How to find Dataset Identifiers and Citations for ONC's Data Access Tools & Products
Oceans 3.0 Search History Tool
The Search History tool is associated with your Oceans 3.0 user login ID, and so when you complete a search, the parameters of your search will be archived in our database, and accessible to you into the future, making it easier to grab the associated citation for the data you actually used! SearchHistory archives all details of a data search that results in “Add to Cart” to “Download”. The Search History interface is simple to navigate, with different ways for users to identify the correct record for their needs. Columns include: An example of these in real life looks like: There are additional details associated with the data search when the user selects the down arrow to the left of the Path column. Additional details include: Below is an example of these. The red outline shows all searches from one search (i.e., if user selects multiple formats to download, or multiple, specific variables). Green outline shows a specific record for that search, and the orange circle shows where you can easily copy the citation. This tool is actively being maintained, and functionalities extended, so check back here for updated documentation pertaining to enhancements! If you have any questions, concerns, or suggestions, please contact us as datacitations@oceannetworks.ca. 


SeaTubeV3
For information about how to cite video or images (e.g., digital stills or frame grabs) in the SeaTubeV3 video viewing and annotation tool, refer to SeaTube Help#CitingVideo/ImagesinPublications.
ERDDAP
Ocean Networks Canada provides access to our data through Oceans 3.0, as well as ERDDAP. ERDDAP provides users an alternative way to query ONC data that may be more visible to them. Full user documentation is available at OPeNDAP Web Services.
We have integrated our DOIs into our ERDDAP infrastructure, allowing users to more easily cite the data they use. The DOI can be found by selecting the 'M' for the record from the search results:
Once M is selected, the DOI can be found at the top portion of the record as the value for the Attribute 'DOI':

The arrow at the end of the DOI will direct the user to the Oceans 3.0 Landing Page described above, where they can find the suggested citation provided by ONC.
ERRDAP does not currently support Query PIDs, due to the fact that they do not archive queries submitted through the service. If users would like to cite the data with a Query PID they are welcome to download the data directly from Oceans 3.0.
Data Products
Several data products contain citation and attribution information wherever feasible, so that data products may be referenced and cited by persistent identifiers. The following data products include citations:
MAT Format
All MATLAB MAT format file products (MAT file Metadata structure - Scalar and MAT file Metadata structure - Complex) contain a metadata structure with citation information.

NetCDF Formats
All NetCDF format files contain a global attribute with the citation text. The attribute is named "id" as specified by the Attribute Convention for Data Discovery under its Highly Recommended category. NetCDF formats are available for some complex data types, such as ADCP data and scalar data in the near future.
Text Files (CSV, JSON, ODV)
All time series text file products (Time Series Scalar Data) have a citation line(s) in their headers with the DOI URLs.
CSV
All non-data entries are preceded by the pound sign (#). Sub-sections are delimited by dashed-lines. The Original sub-section contains the Citation.

JSON
The metadata object in the JSON file contains the Citation in the originSection.

ODV
The file header section contains the metadata including the Citation:

Seismic Data
In order to better serve the seismic community, most of the raw waveform data for seismic instruments from ONC's observatories are archived within the Incorporated Research Institutions for Seismology (IRIS) data repository. As a result, we provide some clarity on citation guidance here.
Raw waveform data in Incorporated Research Institutions for Seismology (IRIS)
ONC's raw seismological waveform data (miniseed format) are archived within the IRIS data repository (operated by the EarthScope Consortium). Instructions on how to properly cite data obtained from IRIS Data Services are given here https://www.iris.edu/hq/iris_citations. Ocean Network Canada's two networks NV and OW landing pages can be found under the International Federation of Digital Seismograph Networks (FDSN):
A citation of the NV and OW networks should be included in the References of the paper, using the DOI's referenced above for the two networks. An example citation for NV as of 2023-01-18 (given in landing page https://doi.org/10.7914/SN/NV) is as follows:
- Ocean Networks Canada. (2009). NEPTUNE seismic stations [Data set]. International Federation of Digital Seismograph Networks. https://doi.org/10.7914/SN/NV
As of 2023-01-18, there is no specific citation for the station or channel levels, but this might change in the future.
IRIS also appreciates authors to notify them of publications in which IRIS is cited, which is the same for Ocean Networks Canada https://www.oceannetworks.ca/science/publications/.
More information on DOIs assigned to seismic networks are provided here: http://fdsn.adc1.iris.edu/services/doi/.
Data and data products stored at ONC
The following data products are stored in ONC's Oceans 3.0 data repository (not in IRIS). These files should be cited in the same way as as other datasets at ONC.
- Ancillary State of Health Files stored in our repository (not IRIS) contain ancillary seismometer information. These files are also converted into standard Log Files, available for download.
- Seismic Test Data are also available in our repository for seismometers or accelerometers that undergo the VAULT testing procedure.
- Seismometer Data products are also offered via Oceans 3.0. This way of downloading seismometer data and products is not recommended and it is better if the end-user obtains the raw waveform data directly from IRIS and processes it to obtain derived products.
Example of a landing page for these files: https://data.oceannetworks.ca/DatasetLandingPage?doidataset=10.34943/325e814b-2011-48a8-a421-dbf82d5456ad.
Web Services
In addition to the DOI/Query PID Search tool, Ocean Networks Canada offers several web services as an alternate method of interacting with data and metadata through our Oceans 3.0 API.
If you are unfamiliar with APIs (Application Programming Interfaces) there are many easy-to-understand introductions available on the web. Try Codenewbie, What Is an API? or APIs 101. APIs are especially useful for automating computer-to-computer processes, such as batch citation downloads or scheduled data retrievals.
Ocean Networks Canada has web service offerings: a data citation text service, and a dataset metadata retrieval service.
Data Citation Text Service
The API citation service returns a citation for a given DOI or Query PID, formatted to ESIP guidelines established by the earth science community. When you call our API service using a DOI or Query PID, it automatically generates a ready citation for that dataset in JSON format, like this:
{"citationText":["Ocean Networks Canada Society. 2015. Central_Strait of Georgia VENUS Instrument Platform_Conductivity Temperature Depth_20-Sep-2014. Ocean Networks Canada Society. https://doi.org/10.21383/5cxhry6t2x. Accessed 2020-02-13."]} |
To learn more about using this service, go here.
Dataset Metadata Service
Given a DOI or a Query PID, you can use the API to retrieve the full metadata record associated with the dataset or query subset. This isn’t a new concept for data citation in general, but the ability to specify a precise subset of data via the Query PID - and retrieve exact details about the timestamp of the query, the time series of the data, and other subset parameters - is a feature unique to ONC.
To learn more about using this service, go here.
Technology Migration Policy
In order to comply with the RDA recommendations requirements for Technology Migration (R13) and Migration Verification (R14), ONC developed a Technology Migration Policy to ensure the data infrastructure ensures sustainable resolution of the dynamic dataset and subset citations.
Dataset Collections
ONC now provides the service of curating dataset collections to users upon request. This functionality would be intended to serve users who download data that spans several datasets, i.e., across multiple deployments. It would allow users to cite the aggregated dataset instead of several singular datasets. For more information on this process and to request a dataset collection please see Collections
Related Projects
MINTED Project
The MINTED project (Making Identifiers Necessary to Track Evolving Data) is funded by the CANARIE Network, and supports Ocean Network Canada’s need to implement PIDs to datasets to be renewed for the CoreTrustSeal, a certification of repositories using best practices.
MINTED aims to integrate dataset citation DOIs and RORs (Research Organization Registry identifiers) into ONC’s Oceans 3.0 digital infrastructure. ONC's data are very dynamic due to continually accumulating data streams, data reprocessing, and data product code versioning. While there has been a growing recognition of the need for and benefits of data citations, as evidenced by the reception of the FAIR Principles, existing platforms and tools such as Dataverse and the Federated Research Data Repository (FRDR) are currently only able to serve the needs of static, or infrequently updated, datasets. At ONC, we have an opportunity to go further, building the infrastructure within our repository to implement the 14 recommendations laid out by the RDA Working Group on Dynamic Data Citation.
MINTED allows data users to cite data in the repository from the beginning of a deployment, providing traceability of the dataset life cycle so that users can better interpret data integrity, respect the terms and conditions under which the data are made available, and increase the credibility of users. Data citation also allows users to link datasets to publication DOIs, contributor ORCIDs or RORs, funder reference IDs, ARK IDs, and more.
It makes strides in enabling reproducibility, provides curated datasets to end users, provides credit for publishing and providing data, helps repositories and users to track metrics of data usage and impact, and enhances metadata catalogues and products for citation content. Additionally, data citation stimulates related research as published datasets that have been cited lend themselves more readily to further analysis.
Lastly, the MINTED project also allows ONC to renew our certification with World Data System (WDS) CoreTrustSeal (CTS), identifying ONC as a repository that has implemented and supports FAIR (Findable, Accessible, Interoperable, and Reusable) data principles and best practices, encouraging confidence in the content within.
With the MINTED Project, Ocean Networks Canada is proud to be leading the way in implementing the RDA Recommendations on a large scale. In partnership with CANARIE, the DataCite Canada Consortium, and our own crack team of software engineers, ONC’s work will help establish best practices for good data stewardship now and into the future.
DynaCITE Project
DynaCITE (Dynamic Citation Identifiers Training and Education) aims to promote the power of PIDs (persistent identifiers) in a comprehensive way that explains their frameworks and emphasizes their value through education, examples, and training. DynaCITE leverages work already successfully completed from the MINTED (Making Identifiers Necessary to Track Evolving Data) project, funded by Research Data Canada and CANARIE Inc. (2018-2020). Ocean Networks Canada’s (ONC) Data Stewardship Team has gained considerable expertise in the implementation of persistent identifiers and data citation as a result of that project, the subsequent two years of operational usage, and early user feedback. Beginning in 2022, ONC will further extend these functions and processes with the ‘ExperiMINTED’ project, which will run in tandem alongside DynaCITE to develop a more comprehensive citation system based on user feedback, operational findings and relevant Research Data Management (RDM) community advances. While the training resources and activities developed for DynaCITE will be based upon the ONC implementation of RDM principles, the benefits extend to the wider research and repository communities due to broadly applicable use cases, identifier services (e.g., DataCITE, Research Organization Registry (ROR)) and challenges (e.g., dynamic data, versioning, query systems, data granularity, metrics). Targeted users and data partners will have the opportunity to give constructive feedback that will inform improvements to our services and frameworks.
DynaCITE is supported in part by funding from the Digital Research Alliance of Canada. See the full list of Data Champions project at https://alliancecan.ca/en/latest/news/announcing-2022-2023-data-champions.
![]()
ExperiMINTED Project
Coming Soon
How to Cite Other Research Objects (other than datasets)
Guidance for citing ONC Oceans 3.0 digital infrastructure
Please cite the below article if you are referencing ONC's digital infrastructure, such as the tools and functions in Oceans 3.0:
Owens D, Abeysirigunawardena D, Biffard B, Chen Y, Conley P, Jenkyns R, Kerschtien S, Lavallee T, MacArthur M, Mousseau J, Old K, Paulson M, Pirenne B, Scherwath M and Thorne M (2022) The Oceans 2.0/3.0 Data Management and Archival System. Front. Mar. Sci. 9:806452. doi: 10.3389/fmars.2022.806452
https://www.frontiersin.org/articles/10.3389/fmars.2022.806452/full
Guidance for citing ONC's Oceans 3.0 data repository (entity)
Please use the below citation if you are referring to Ocean Networks Canada data repository services:
re3data.org: Oceans 3.0 Data Portal; editing status 2025-03-27; re3data.org - Registry of Research Data Repositories. http://doi.org/10.17616/R3RW43 last accessed: YYYY-MM-DD
Future Plans
This CANARIE funded project ends March 31, 2020, but ONC intends to leverage the work done within the parameters of the initial project proposal to enhance the value for our community.
ONC has done extensive research on schema.org and is working to implement these conventions to extend our reach to users outside of the Oceans community, allowing data to be findable through Google Dataset Search. We have a representative in both ESIP and RDA schema.org Working Groups who is immersed in the community conversation on how best to implement this in the geosciences.
ONC maintains partnerships with many other research organizations and thus has already implemented RORs in MINTED outputs, but additionally we aim to include ORCIDs for individual researchers who are interested in partnering with ONC, or preserving their data within our Oceans 3.0 database. ORCIDs will allow contributors to be credited appropriately and universally for their intellectual work in the production of data in our system. ORCIDs streamline the process of accurately identifying a specific researcher, since personal names can be represented in several ways and belong to more than one individual, e.g., it is not always clear if Jane Smith is Jane Marie Smith, J. Smith, Dr. J. Smith, J. M. Smith, etc.
Another important feature slated for development is the implementation of W3C’s PROV model within our system. Currently, our existing provenance model focuses on activities undertaken only after data is ingested into Oceans 3.0, such as reprocessing data and assigning a new DOI for reprocessed data; however, it is also important for users to understand how data is received and parsed from the instrument from the beginning, as well as how derived data is produced. This was outside of the scope of the project within the CANARIE funding period, but efforts to develop this feature are impending.
ONC has data partners where we host the data they collect, but we also have data partners who host ONC-collected data on their own repositories, such as the Incorporated Research Institute of Seismology (IRIS). In instances like this, we host ancillary data associated with the data we send to IRIS, and we are planning to tag the XML document with the RelatedIdentifier associated with RelationType. This will allow for users to better identify and access data that relates to it outside of Oceans 3.0. Linked Data is a best practice in Web 2.0 technology, and allows organizations to leverage their relationships in structured ways.
Additionally, ONC is engaged with the Make Data Count Project, which focuses on identifying how best to track metrics related to data. Their intent is to learn whether metrics that currently relate to other research outputs, such as journal articles, are appropriate for datasets as well. ONC is interested in tracking the use of our data in meaningful ways for our data partners and funders, as well as improving our support and services.
Recommended Resources
Below is a list of resources (in order of presentation) for users interested in learning more about data citation:
- Journal article about data subset identification, referencing MINTED: Rauber, A., Gößwein, B., Zwölf, C. M., Schubert, C., Wörister, F., Duncan, J., … Parsons, M. A. (2021). Precisely and Persistently Identifying and Citing Arbitrary Subsets of Dynamic Data. Harvard Data Science Review, 3(4).https://doi.org/10.1162/99608f92.be565013
- Portage Webinar about the MINTED project: https://www.youtube.com/watch?v=pcUtXpcqqJw
- RDA 14 Recommendations for Data Citation: https://www.rd-alliance.org/system/files/documents/TCDL-RDA-Guidelines_160411.pdf
- FAIR Data Principles: https://www.force11.org/group/fairgroup/fairprinciples
- WDS CoreTrustSeal Data Repository Requirements: https://www.coretrustseal.org/why-certification/requirements/
- Research Organizations Registry: https://ror.org/
- ESIP schema.org WG: http://wiki.esipfed.org/index.php/Schema.org_Cluster
- RDA schema.org WG: https://www.rd-alliance.org/group/data-discovery-paradigms-ig/post/rda-ddpig-task-force-using-schemaorg-research-dataset
- Schema.org: https://schema.org/
- ORCID: https://orcid.org/
- The FREYA Project:https://www.project-freya.eu/en/about/mission
- ESIP Data Citation Guidelines for Earth Sciences: https://esip.figshare.com/articles/Data_Citation_Guidelines_for_Earth_Science_Data_Version_2/8441816
- COPDESS: https://copdess.org/enabling-fair-data-project/
- W3C PROV model: https://www.w3.org/TR/prov-overview/
- Make Data Count: https://makedatacount.org/
- *Rescognito: https://rescognito.com/
*Not mentioned in the above document, but:
Rescognito is a new, free, and easy to use support service for linking scholarly publications, and digital resources, to the researchers involved, through their ORCIDs using DOIs. When a dataset is linked by a researcher, it will automatically generate an interactive data availability checklist (providing at least one of the contributors have an ORCID). Data availability checklists earn users COGs - units of recognition. Rescognito also aggregates recognition ledgers to assess the author compliance with and contributions to open scholarship - these are available for funders, academic institutions, and publishers to view.
Rescognito is suggested as a post-publication step for datasets, to gain recognition as a contributor to open data.
Contact Us For Assistance
For assistance or further enquiries, please email us a datacitations@oceannetworks.ca.